1. Abstract
Machine learning (ML) has recently emerged as a major technique in financial forecasting due to its potential to model non-linear relationships in data and to analyze large datasets. Although numerous studies demonstrate the ability of ML to generate accurate predictions in financial forecasting, empirical results indicate that ML models do not consistently produce better predictions than those generated using traditional econometric methodologies. To address these differences in forecasting methodology, this research identifies the structural impediments to ML in financial forecasting, specifically including over-fitting, nonstationarity, regime shifts, and low signal-to-noise ratios. Furthermore, based upon academic literature and practical application challenges, this research proposes an adaptive hybrid model that combines the strengths of ML models with the theoretical foundations of economics. Additionally, this research utilizes robust validation techniques and includes governance mechanisms in order to evaluate the effectiveness of the ML model. The results of this research indicate that the use of ML is most beneficial as a complimentary tool for generating additional information about future outcomes in addition to being used as a predictive modeling tool.
2. Introduction
Machine learning (ML) has been heavily promoted as a transformative technology in financial forecasting for all three areas of financial forecasting: macroeconomic forecasting, asset pricing forecasting and corporate finance forecasting. Initially, studies indicated that ML models were capable of producing superior forecasts compared to traditional linear models as they provided the capability to capture complex and non-linear patterns in data (Gu, Kelly & Xiu, 2020). Despite the early optimism regarding the benefits of ML models in providing superior forecasts, subsequent empirical analysis has demonstrated that while ML models tend to provide excellent forecast performance within the sample period of analysis, they also tend to fail to generalize well outside of the sample period of analysis; especially within dynamic financial environments (López de Prado, 2018).
The disparity in performance between ML models and traditional linear models stems from a number of structural characteristics inherent in financial systems. Specifically, financial data is characterized by non-stationarity (i.e., changes in variance), structural breaks (i.e., changes in relationship structure), and low signal-to-noise ratios (i.e., little relationship exists between independent variables and dependent variable); all conditions in which the underlying assumptions made by standard machine learning models tend to be violated. Therefore, this paper will:
- Identify key structural constraints that limit the performance of ML models in financial forecasting.
- Review relevant empirical and theoretical support for these constraints.
- Propose a practical approach for incorporating AI into financial forecasting.
3. Structural Limitations of ML in Financial Forecasting
-
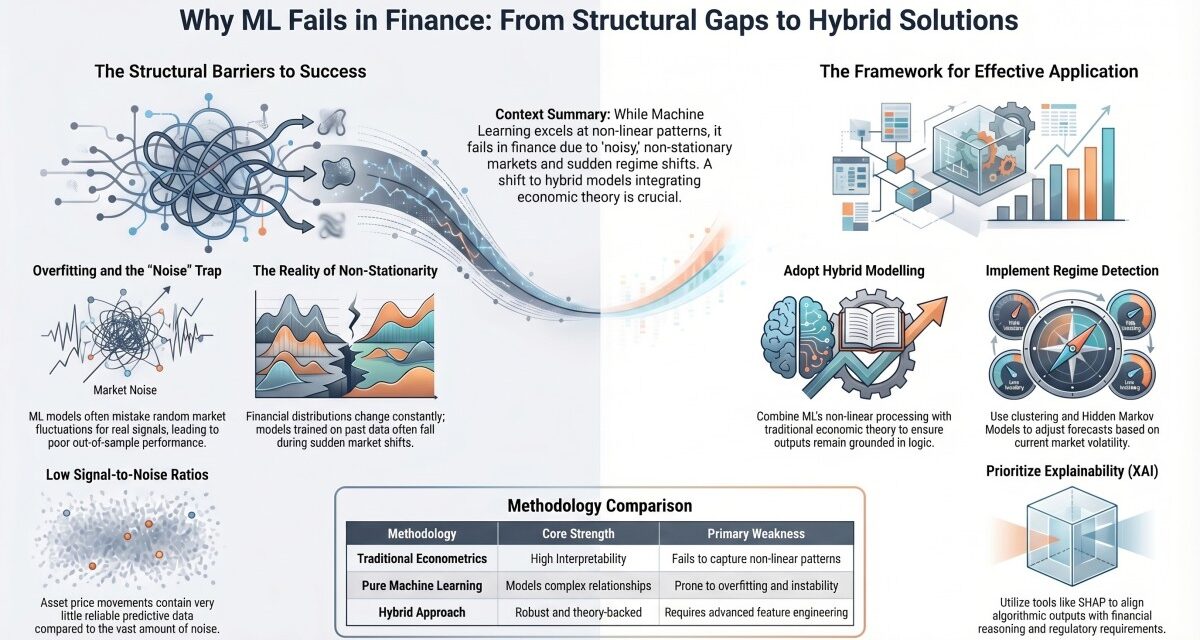
Overfitting and Spurious Correlations
ML models are optimized to minimize the difference between predicted and actual values of the dependent variable using historical data. As a result, there is always a risk of over-fitting in financial forecasting. When there are many independent variables in a dataset (a common occurrence in financial data), ML models may fit noise rather than true relationships. Empirical studies have shown that many predictive signals found by ML models lose power after leaving the sample (Harvey, Liu & Zhu, 2016). These effects are likely compounded by data mining biases and multiple testing.
-
Non-Stationarity of Financial Time Series
Financial time series are inherently non-stationary. Their statistical properties change over time. Structural breaks occur in response to macro-economic events, regulatory changes, technological innovations etc. All machine learning models rely on the assumption that the training and test data are sampled from the same distribution. When this assumption fails (and it usually does in practice) then the resulting model is unstable and less useful for predicting.
-
Regime Shifts and Structural Breaks
There exist different regimes in financial markets. For example: volatile times during crises vs. quiet times during expansions. Models developed in one regime will generally perform poorly in other regimes. It has been documented that neglecting regime dependence can cause serious declines in forecasting performance (Ang & Timmerman, 2012). Regime-switching models like Hidden Markov Models have been developed to handle this problem.
-
Low Signal-to-Noise Ratios
One of the biggest problems faced by practitioners when attempting to predict asset prices is the extremely low signal-to-noise ratio associated with price movements. Even very sophisticated machine learning algorithms find it challenging to uncover reliable predictive relationships among asset returns given how inefficiently capital is allocated in markets where investors behave rationally (Fama, 1970; Gu et al., 2020).
-
Data Quality/Feature Engineering Challenges
Financial datasets are subject to quality issues such as missing observations, delayed reporting and revisions. Also important economic indicators like investor expectations and sentiment are often difficult to quantify. Research indicates that feature engineering plays a much larger role than choosing which type of machine learning algorithm to employ (Lopez De Prado, 2018).
-
Lack of Economic Interpretability
A significant limitation on the adoption of many types of machine learning algorithms is their lack of interpretability. Many machine learning algorithms including ensemble methods and deep neural networks cannot be easily interpreted. As a result, this limits their adoption within regulated industries as regulators require clarity for decision making purposes and regulatory compliance (e.g. explainability requirements now exist under current regulation).
-
Biases Associated with Back Testing
Back-testing represents a commonly employed method for assessing whether or not a machine learning model has sufficient merit to be deployed. However, back-testing is susceptible to a variety of biases including: look-ahead bias, survivorship bias, data leakage (Bailey et al., 2014). All of these biases represent potentially severe inflation of model accuracy and thus may lead to incorrect conclusions.
-
Key Insight
Although using machine learning in financial forecasting does enable us to generate forecasts based on data, it does not necessarily enable us to generate forecasts based on our ability to anticipate what will occur. Therefore, in addition to the degree to which any given model predicts future occurrences of the event being forecasted, the model itself also needs to be stable (resistant to extreme values), produce similar estimates over time and represent the economics of the event(s) being modeled.
4. Framework for Using Machine Learning to Improve Financial Forecasting Performance
-
Combine ML with Economic Theory (Hybrid Models)
Rather than replace traditional statistical modeling methods with machine learning (ML) as part of the forecasting process, the two should instead be used in conjunction. for example, a traditional statistical model may determine the linear components of a relationship while a machine learning model determines the nonlinear residuals. Research studies have shown that hybrid model approaches (gu et al., 2020) are often superior to traditional statistical models or machine learning models used separately.
-
Use Rolling Window and Adaptive Models
As markets continue to evolve, forecasting models must adapt. One way to accomplish this is through the estimation of parameters within rolling or expanding windows. This enables the model to continually reflect changing market conditions.
-
Regime Detection and Segmentation
By determining different regimes of the economy and then producing forecasts for each regime, researchers can improve forecast accuracy. Ang and Timmerman (2012) describe several examples of how economists use clustering techniques and Hidden Markov Models (HMMs) for regime detection/segmentation.
-
Stress Testing and Cross Validation
When assessing the quality of a model, we need to focus on its robustness (its ability to survive stress testing) rather than simply on its ability to fit past data. Cross validation and ensemble modeling provide means to decrease model variance and enhance model stability.
-
Advanced Feature Engineering
Feature engineering should always follow theoretical expectations based on economic principles. When adding new features to a model (such as macroeconomic variables, lagged variables and alternate forms of data), we can normally expect improved prediction performance.
-
Rigorous Backtesting Protocols
To ensure that your evaluation of a model represents how you expect a model to behave in a “real world” setting, you need to employ walk forward validations and simulation protocols. Both of these methods assist in removing potential biases found with traditional historical backtesting evaluations.
-
Explainable Artificial Intelligence (XAI)
Explainable artificial intelligence (XAI) tools, like SHAP (Shapley Additive Explanations), allow for enhanced interpretation and align output from an ML model with expected financial reasoning processes.
-
Scenario-Based Forecasting
Whereas ai is clearly able to develop point predictions concerning future events, ai can also be employed for developing scenarios. Scenario-based forecasting allows decision-makers to evaluate possible futures in a manner that is much more conducive to decision-making under uncertainty.
-
Human-in-the-Loop Systems
Regardless of how sophisticated machine learning becomes, there is still significant value added in utilizing machine learning in conjunction with human knowledge about an individual market, asset class or industry for improving decision-making outcomes.
-
Model Risk Management (MRM)
Specifically-designed governance frameworks for managing risks associated with the development and deployment of financial models are required for monitoring performance, detecting trends/drift, etc., and complying with regulatory requirements.
5. Conclusion
Machine learning does not perform as well as anticipated in many areas of financial forecasting due to the inherently dynamic and complex nature of financial systems. Specifically, the non-stationary nature of financial systems coupled with regime shifts and generally low signal-to-noise ratios create an environment where purely data-driven approaches will not suffice.
Existing literature indicates that machine learning will perform well when it is used as a complement to economic theory, an adaptive modeling strategy, or an effective governance framework. Therefore, future research should focus on developing hybrid models that provide both good predictive performance and interpretability for use by finance professionals in making financial decisions.
References
- Ang, A., & Timmermann, A. (2012). Regime changes and financial markets. Annual Review of Financial Economics, 4, 313–337.
- Bailey, D. H., Borwein, J., López de Prado, M., & Zhu, Q. (2014). The probability of backtest overfitting. Journal of Computational Finance, 20(4), 39–69.
- Fama, E. F. (1970). Efficient capital markets: A review of theory and empirical work. Journal of Finance, 25(2), 383–417.
- Gu, S., Kelly, B., & Xiu, D. (2020). Empirical asset pricing via machine learning. Review of Financial Studies, 33(5), 2223–2273.
- Harvey, C. R., Liu, Y., & Zhu, H. (2016). …and the cross-section of expected returns. Review of Financial Studies, 29(1), 5–68.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Tsay, R. S. (2010). Analysis of Financial Time Series (3rd ed.). Wiley.
{kind=link}